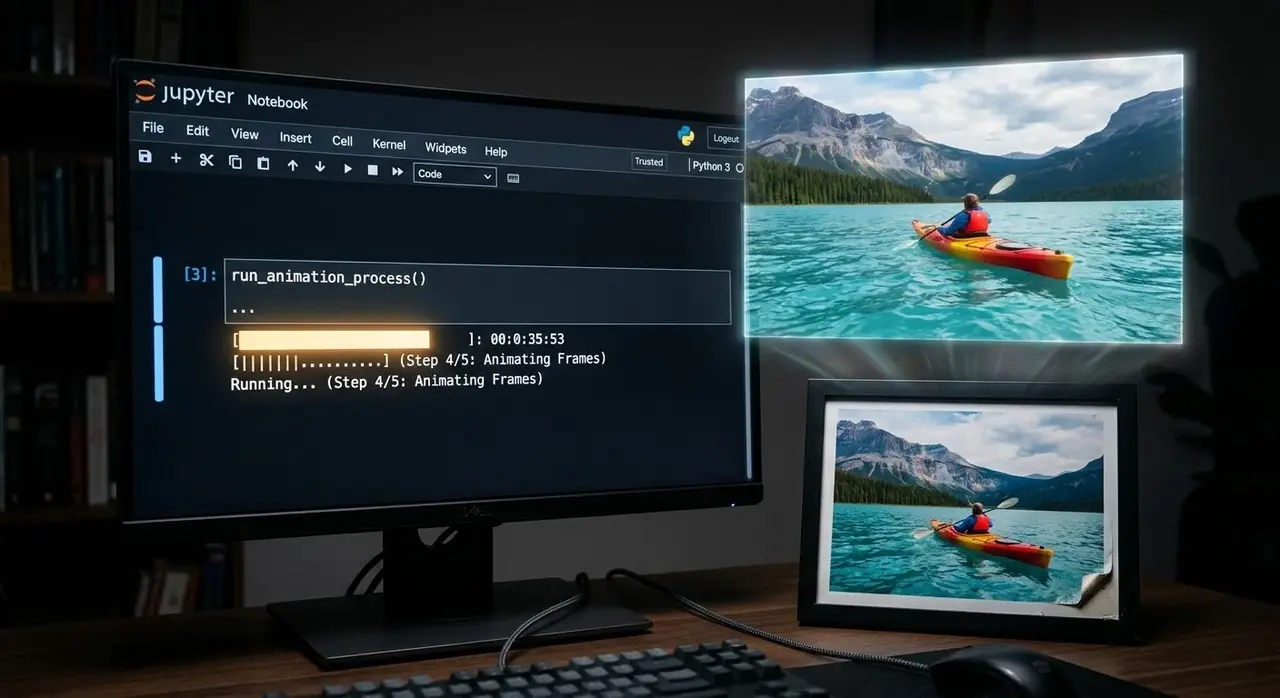
Your vacation photo can now star in its own short video commercial — if you're willing to babysit a Jupyter notebook.
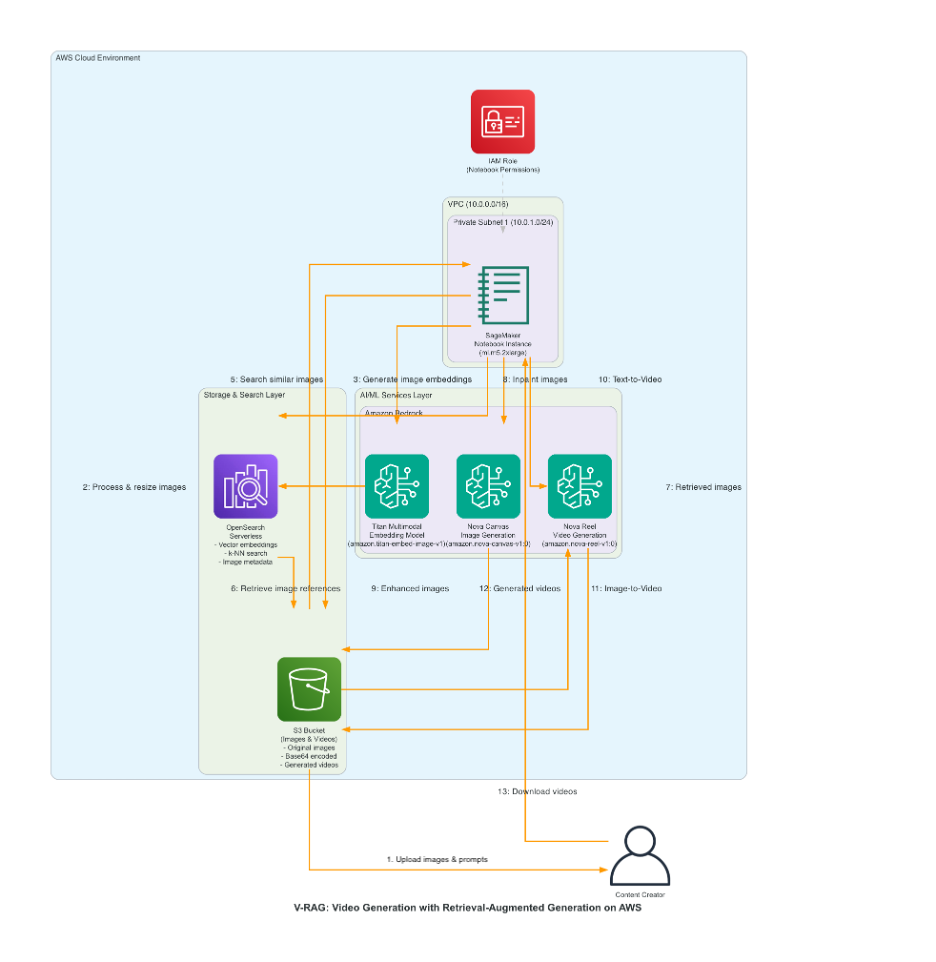
Amazon Web Services published a step-by-step guide this week for building a Video Retrieval Augmented Generation pipeline, or VRAG, using four existing AWS services: Amazon Bedrock, Amazon Nova Reel, OpenSearch Serverless, and S3. A CloudFormation template deploys the entire stack in the US East (N. Virginia) region with a single click. You pay only for what you use — no flat fee listed.
The core idea is straightforward. Drop a library of images into S3. Let Amazon Titan generate vector embeddings for each one. Index those vectors in OpenSearch Serverless.
Then write a structured prompt — something like "Camera rotates clockwise" paired with "blue sky" and the pipeline retrieves the most relevant image from your library, feeds it alongside your text into Nova Reel, and returns an MP4.
Seven sequential Jupyter notebooks walk through each stage: image processing, vector ingestion, text-only video generation, text-plus-image generation, multi-modal RAG retrieval, in-painting, and a final enhanced-video export.
AWS provides working examples throughout — a handbag photo that generates its own product description, a seashell prompt that produces a slow camera zoom, a kayak scene generated first from text alone and then again with a specific reference image to show the difference.
AWS is candid about where the pipeline falls short. The authors note that "quality of the generated video is heavily dependent on the quality and relevance of the image database used in RAG" and that "additional video editing techniques might be required to create a polished final product." The system handles retrieval and generation. Color grading, audio, and final assembly remain the editor's job.
The practical ceiling is also worth noting. Nova Reel operates asynchronously — jobs are submitted, monitored, and retrieved when complete rather than processed instantly. The solution is designed for batch production from a structured prompts.txt file, making it better suited to repeatable workflows than one-off creative requests.
For teams already running workloads on AWS, the stack slots into existing infrastructure without new vendor relationships. For everyone else, the prerequisites an active AWS account and familiarity with SageMaker notebook instances set a floor that rules out non-technical users.
Source: AWS